Mining Your Gmail Data - Part 6
/First off, let's take a look at the second question that came up at the end of the last post: ignoring the Media Type (the 'application/', 'video/', etc.) from the MIME type.
That turns out to be pretty easy - the script from last time already collected that data, because MimeKit already made it available. We just need to adjust our pandas script to group on 'MediaSubtype' instead of 'MimeType':
types = notFromMe.groupby(['MediaSubtype'])
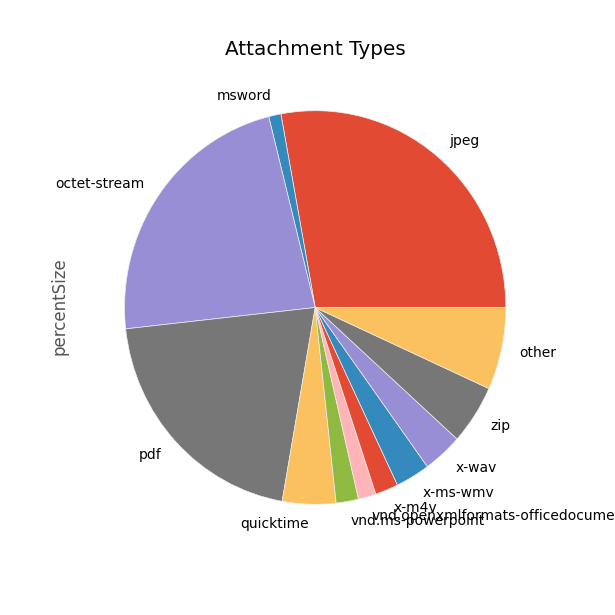
That cleaned things up a lot. But we still have the second question from the last post: what's behind octet-stream?
Application/octet-stream is basically the generic binary file option; most likely the original client which uploaded the file didn't specify the type. But we can make an educated guess about the type based on the file name extension, where we have it. So we'll write a quick function which takes a row of data and, if the Media Subtype is 'octet-stream', returns the file name extension from the FileName column:
import os.path
...
def filetype(row):
if not(isinstance(row['ContentTypeName'], str)):
return ''
if row['MediaSubtype'] == 'octet-stream':
return os.path.splitext(row['ContentTypeName'])[1]
return row['MediaSubtype']
We can run that function against our data and put the results in a new column which we'll call 'FileType':
notFromMe['FileType'] = notFromMe.apply(lambda row: filetype(row), axis = 1)
Now, instead of grouping by MediaSubtype, we just group by FileType. This isn't perfect - some of our data is getting discarded because there's not enough info between Media Subtype and FileName to figure out what kind of attachment it is. But the data is mostly good, and gives us a much more useful chart:
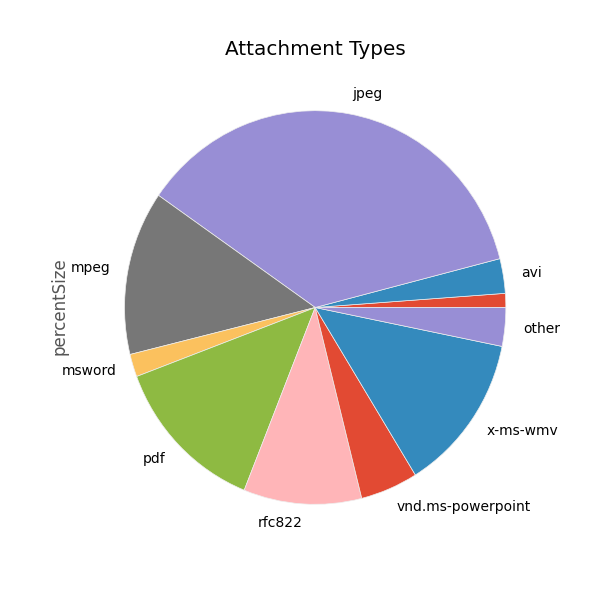
I'm also running this chart with a threshold of 0.02 for the 'other' section, to clean up the less-frequent file types. The whole script can be found here.
So, if I'm looking to downsize my Gmail backup, I should probably concentrate on JPEGs, videos (wmv and mpeg), and PDFs.